TreeSet
- 이진 검색 트리 (binary search tree) 라는 자료구조의 형테
- 정렬, 검색, 범위검색 에 높은 성능을 갖고 있다.
- 중복된 데이터 저장 허용 X
- 정렬된 위치에 저장하므로 저장순서를 유지 X
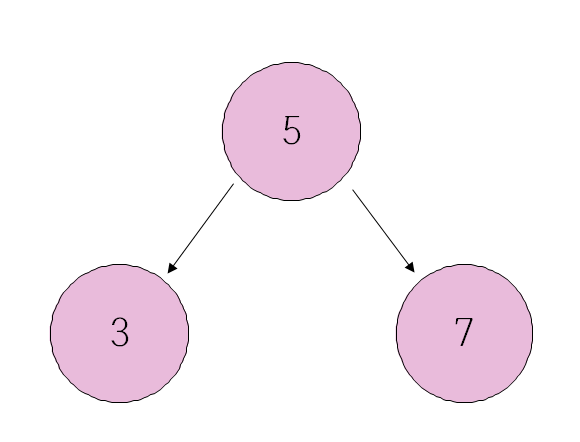
- 노드간의 연결된 모양
- 부모노드의 왼쪽에는 부모노드의 값보다 작은값의 자식노드 , 오른쪽에는 큰 값의 자식노드를 저장
*이진 검색 트리 구조

- TreeSet에 저장되는 객체가 Comparable을 구현하던가 Comparator를 제공해서 두객체를
비교할 방법을 알려줘야한다 그렇지 못하면 TreeSet에 객체를 저장할 때 예외발생
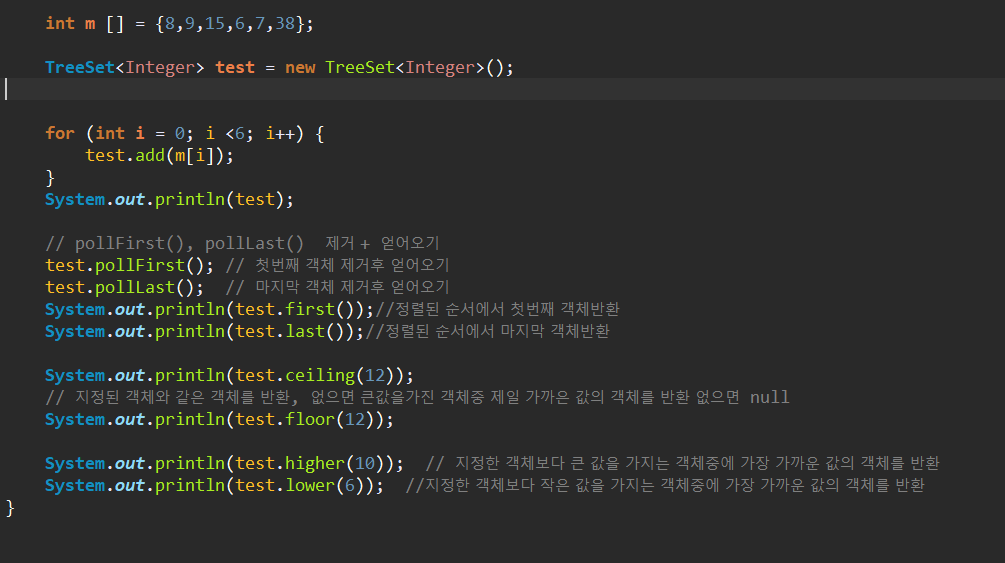
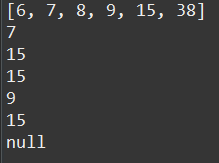
** TreeSet : 정렬, 검색, 부분 검색 성능 빠르지 설명.. 이해...


이진 검색 트리 (binary search tree)
- 모든 노드는 최대 두 개의 자식노드를 가질 수 있다. // 세개이상 ㄴㄴ
- 왼쪽 자식노드의 값은 부모노드의 값보다 작고 오른쪽 자식노드의 값은 부모노드의 값보다 커야함
- 노드의 추가 삭제에 시간이 걸림 (순차적으로 저장하지 X)
- 검색과 정렬에 유리
- 중복된 값을 저장 X

* HashMap & HashTalbe
- String클래스 사용이 불변
- StringBuffer 쓰레드 동기화 처리 O
- StringBuilder 쓰레드 동기화 처리 X
*Array
- ArrayList = 동기화 처리 X
- Vector = 동기화 처리 O
- HashMap = 동기화 처리 X // 새로나온 것이라서 [권장.] key,value - null 허용
- HashTable = 동기화 처리 O
동기화 처리 O = StringBuffer, Vector, HashTable 해싱기법(hashing)많은 양 검색할때 성능이 뛰어나다
동기화 처리 X = StringBuilder, ArrayLis, HashMap
* Map 계열의 특징 : (key + value) == entry 엔트리
- 중복 x 중복 o
- 유일
* 제네릭
< K, V> Key, Value
*Key
- Element
- Type
-자료형 (대문자)
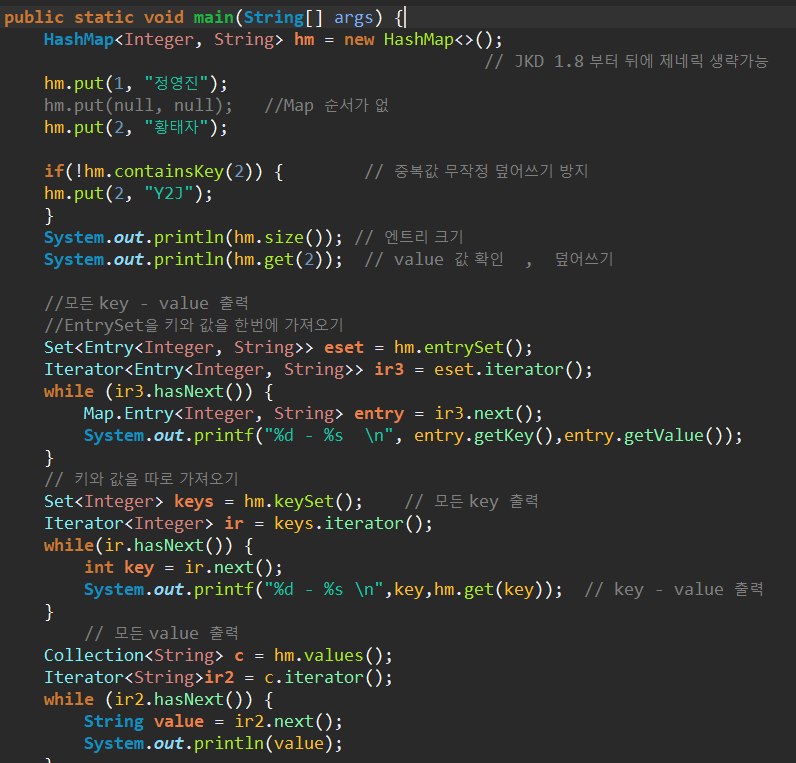

해싱 & 해싱함수
[해싱] : (해시함수)를 이용해서 데이터를 (해시테이블)에 저장하고 검색하는 [기법].
[해시함수] : 데이터가 저장되어 있는 곳을 알려준다. 다량의 데이터에서도 원하는 데이터를 빠르게 찾을 수 있다.
- 해싱을 구현한 컬렉션 클래스 : Hashtable, HashSet, HashMap
- 해싱기법 = 배열 + linkedList(자료 구조)
Properties 컬렉션 클래스
1. HashMap의 구버전(권장)
2. Hashtable을 상속받아 구현.
3. 특징 : Map계열
key-value
String-String (key와 value 자료형이 String)
4. 사용 : 어플리케이션의 환경설정
데이터를 파일로부터 읽고/쓰기 작업.
TreeMap
- 이진검색트리의 형태로 키와 값이 쌍우로 이루어진 데이터를 저장
- 검색과 정렬에 적합한 컬렉션 클래스
- HashMap이 TreeMap보다 더 뛰어나므로 HashMap 사용을 권장
(하지만!) 범위검색이나 정렬이 필요한 경우 TreeMap 사용
Properties
- HashMap의 구버전인 Hashtable 상속 구현한 것
- Hashtable은 키와 값을 Object형태로 저장하는데 Properties는 String 형으로 단순화된 컬렉션 클래스
- 애플리케이션의 속성을 저장하는데 사용
- 데이터를 파일로부터 읽고 쓰기를 제공
- 저장한 키 (key) 값을 읽어오는데 존재하지 X 면 지정된 기본값을 반환
- 저장순서를 유지하지 X
Collections
- Arrays 가 배열과 관련된 메서드를 제공하는 것 처럼 컬렉션은 fill(), copy(), sort(), binarySearch() 등
컬렉션클래스에서도 모두 포함되어 있으며 같은 기능을 함.
- 동기화


<주의!>
Collection = 인터페이스
Collections = 클래스